
はじめに
機械学習と聞くと、私のような文系出身のエンジニアにとっては、「高度な数式の理解が必要そう。」など、障壁が高いもののように感じられます。しかし、IBM CloudのIBM Watson Studioというサービスを利用すれば、機械学習モデルの作成からデプロイして使用するまでコードを一切書かずにできるということで、世界最大級の機械学習のコンペサイトである「kaggle」でチュートリアルとして公開されているタイタニックの生存率予測のモデル作成に挑戦してみました。
手順
まずは今回の取り組みの手順を紹介します。
1.環境の準備
2.トレーニングデータのアップロード、整理
3.モデルの作成
4.モデルのデプロイ
5.モデルの使用
以上5ステップになります。
それでは実際にインスタンスの作成から予測まで行っていきたいと思います。
1.環境の準備
始めにIBM Watson Studioのインスタンスの作成を行います。プランによってはお金がかかってしまうので注意してください。
 今回は機械学習モデルを作成するため、同様にMachine Learningのインスタンスも作成します。
今回は機械学習モデルを作成するため、同様にMachine Learningのインスタンスも作成します。
インスタンスの作成が終わったらIBM CloudのダッシュボードからIBM Watson Studioの管理画面でGet StartedをクリックしGUIを起動します。
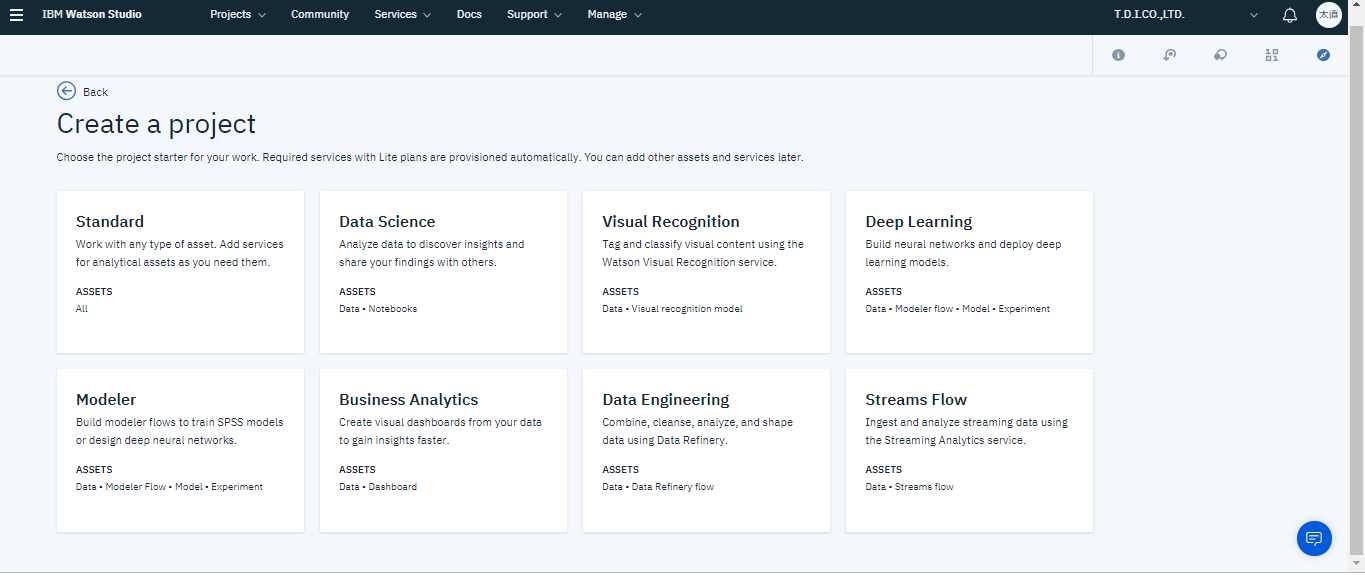
GUIが起動したらCreateProjectを選択し新規プロジェクトの作成を行います。今回は機械学習モデルの作成を行うためModelerを選択し、必要な情報を入力しプロジェクトを作成します。
 プロジェクトの作成が行えたらMachine Learningのインスタンスの紐づけを行います。
プロジェクトの作成が行えたらMachine Learningのインスタンスの紐づけを行います。
Setting画面のAssociated servicesの所でAdd Serviceを選択し、先ほど作成したMachine Learningのインスタンスを選択してください。
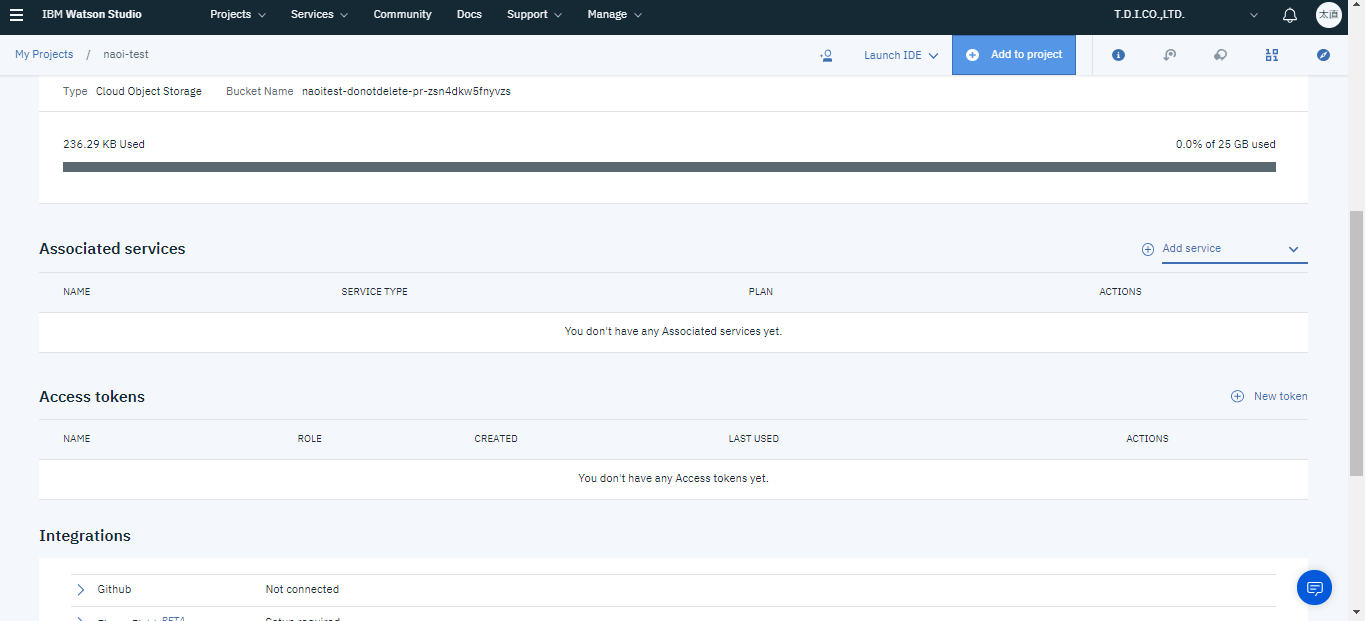
以上で準備が完了しましたので次のステップに進みます。
2.トレーニングデータのアップロード、整理
まずは今回の検証で用いるタイタニックのデータをkaggleからダウンロードしてきます。
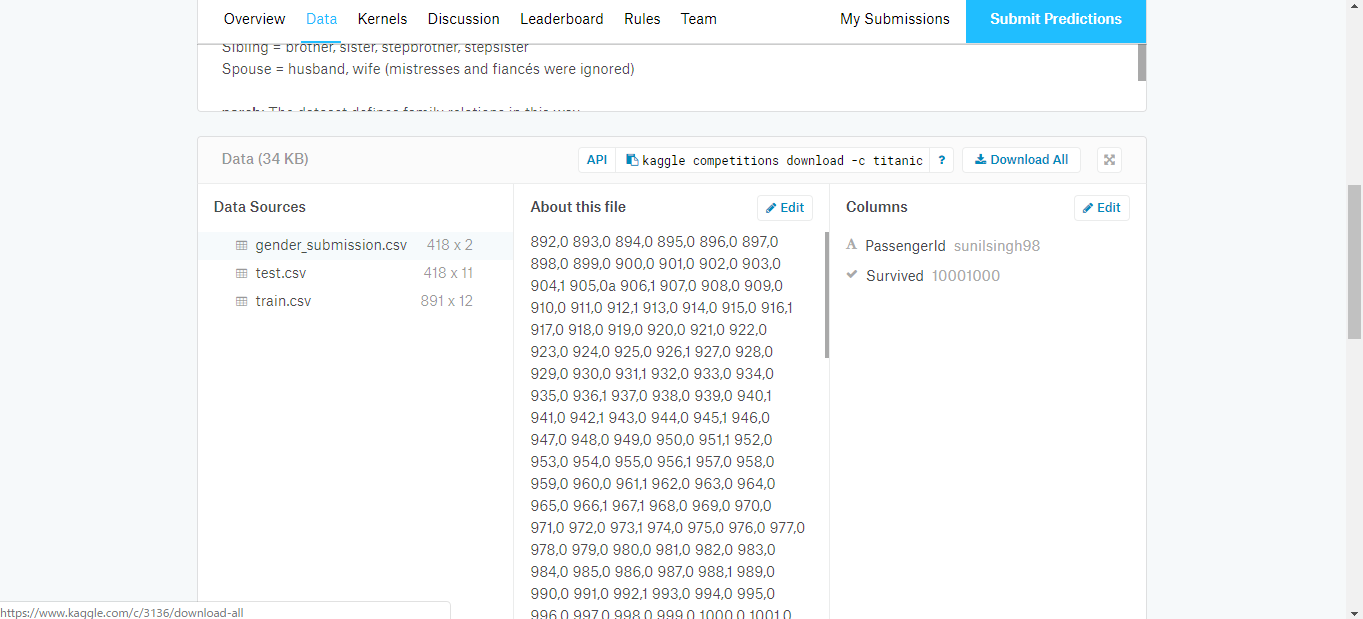
データのダウンロードが完了したら、ダウンロードしたtrain.csvデータをIBM Watson Studioにインポートします。
プロジェクト管理画面の右上にあるFind and add dataを選択し、Loadタブにcsvファイルをドラッグアンドドロップします。
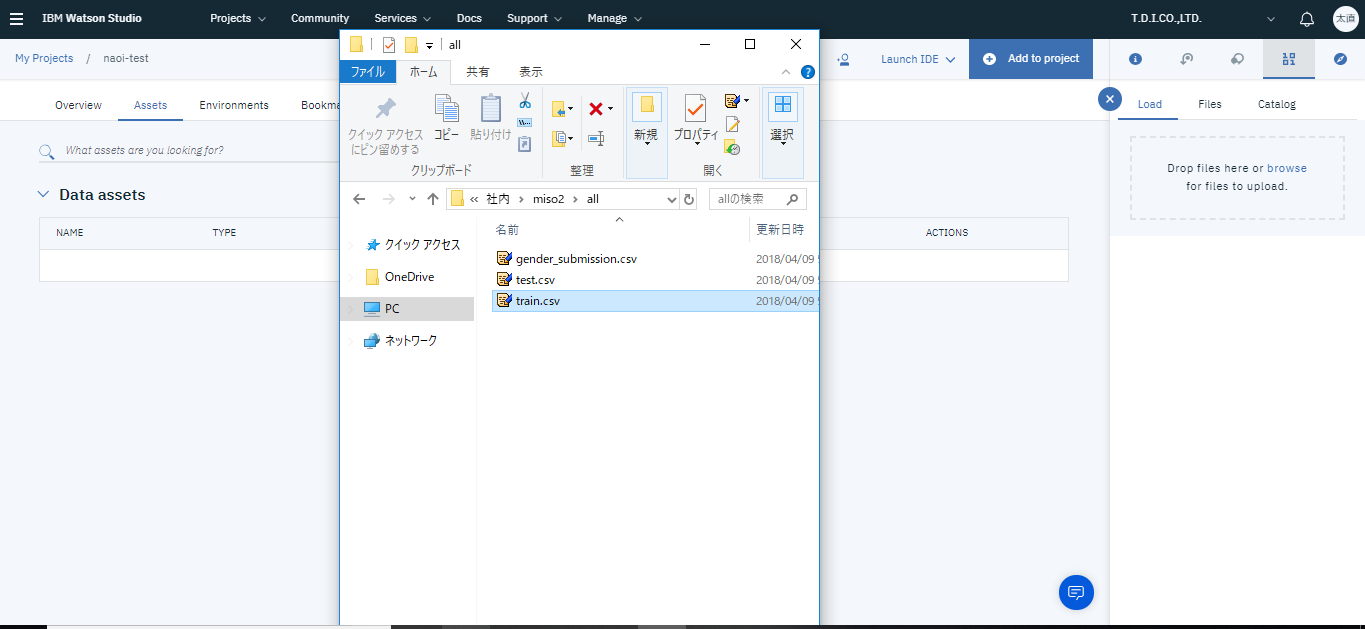
インポートが完了するとプロジェクト管理画面のAssetsタブにtrain.csvが表示されるので、クリックすればデータを確認できます。
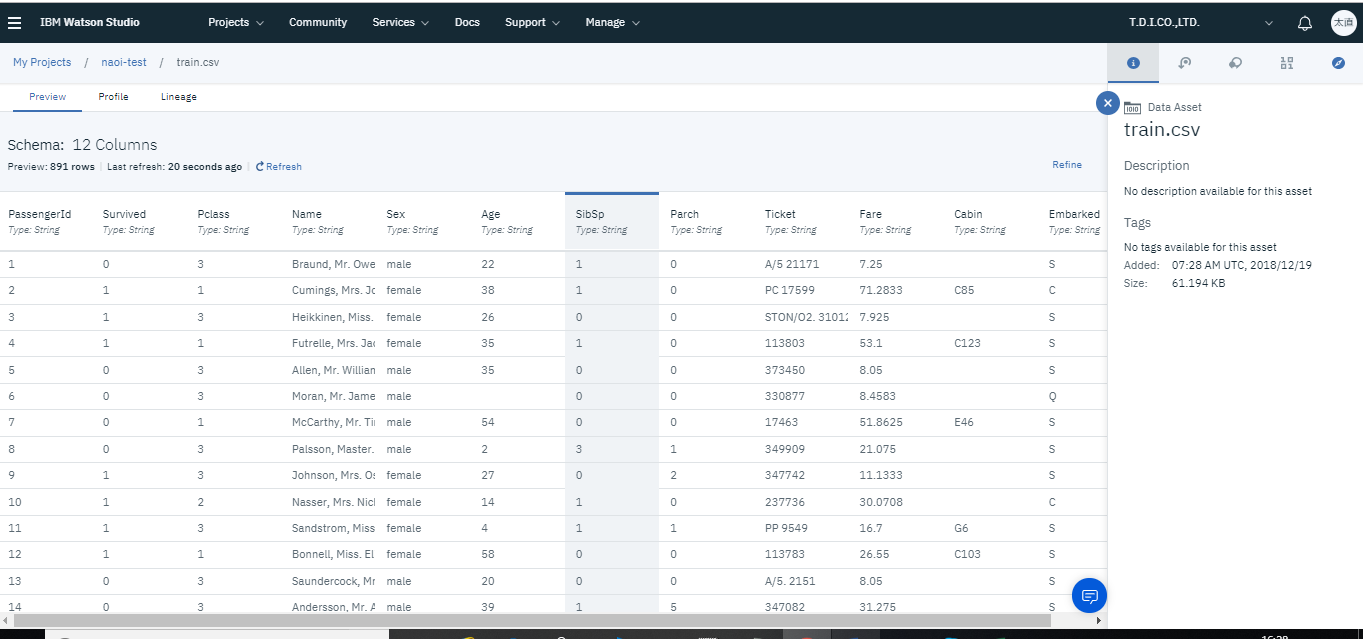 データのインプットが完了したらデータの型変換や欠損値を持つデータの削除など、下準備を行います。
データのインプットが完了したらデータの型変換や欠損値を持つデータの削除など、下準備を行います。
画面上部のAdd to projectからDATA REFINERY FLOWを選択します。
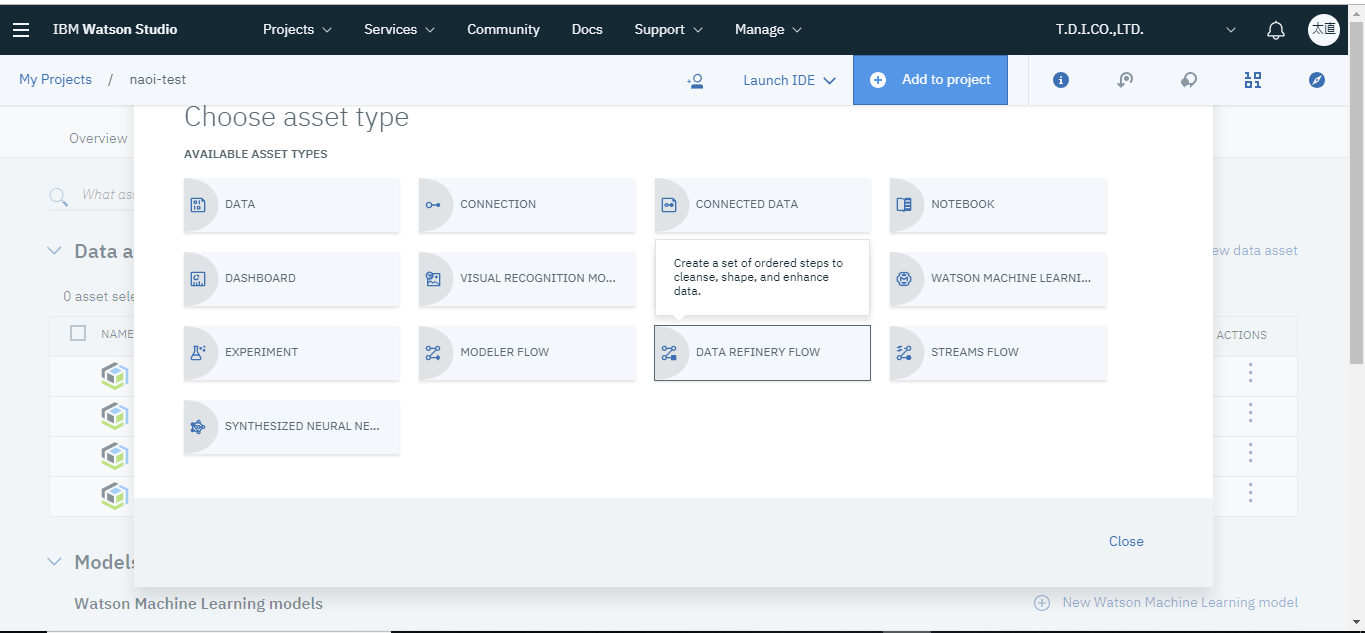
画面が切り替わったら先ほどインポートしたデータを選択しAddをクリックします。
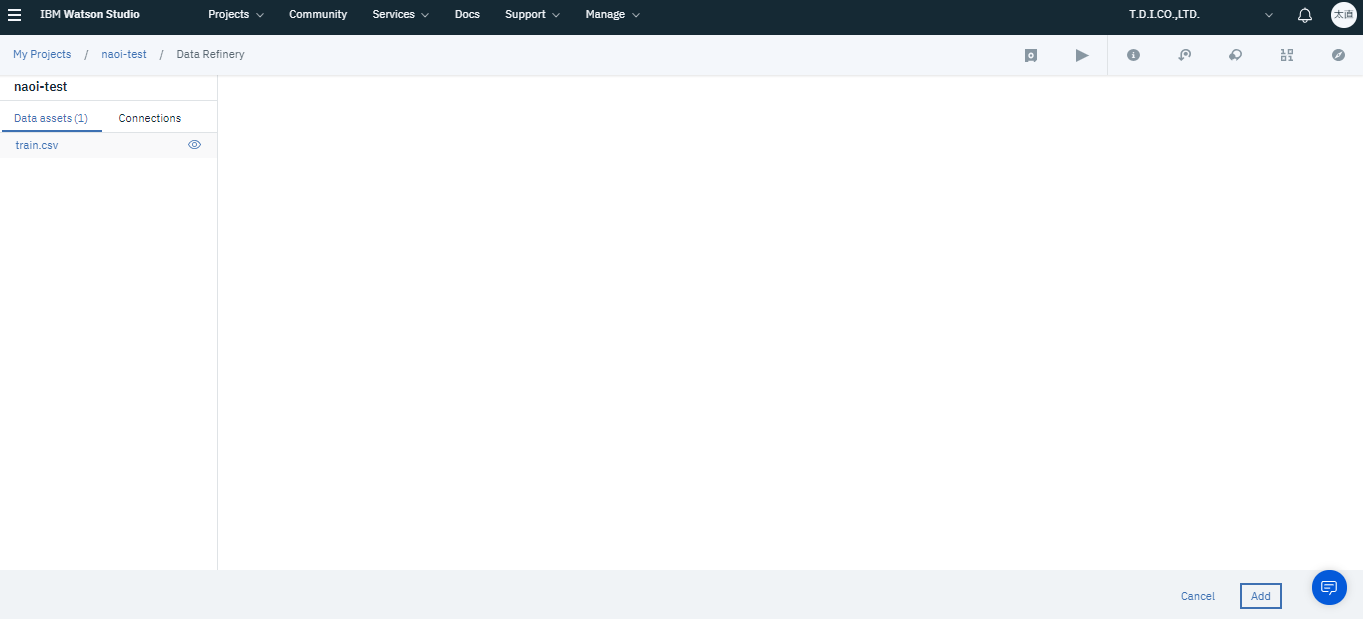
ここでは、下記2つの事を行います。
(1) 欠損値の削除
まず画面左上のOperationをクリックし、Filterを選択します。そしてColumnに欠損値を省きたい列を選択し、Operatorをis not emptyとします。
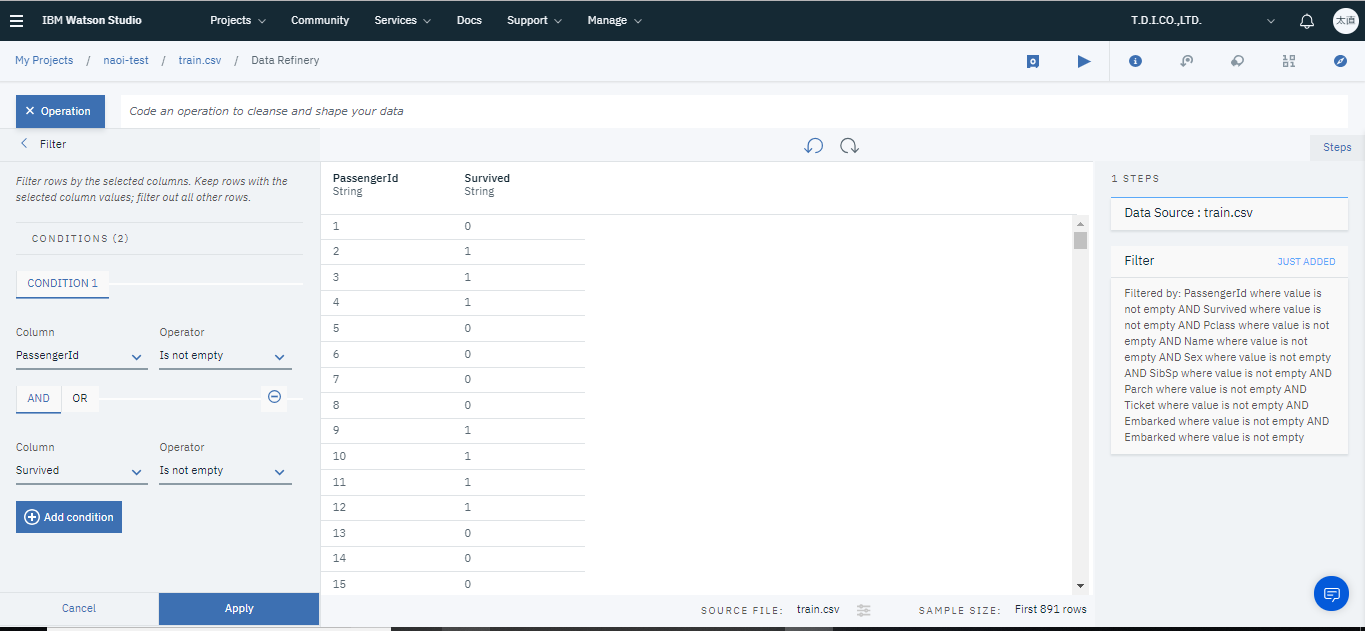
これで対象列の欠損データを省けます。
(2)型の変換
インプットされたデータはデフォルトだと全てString型となっているので、乗客IDや年齢等の数値データを数値型に変換します。
列名右のメニューからCONVERT COLUMN TYPEを選択しIntegerを選択します。
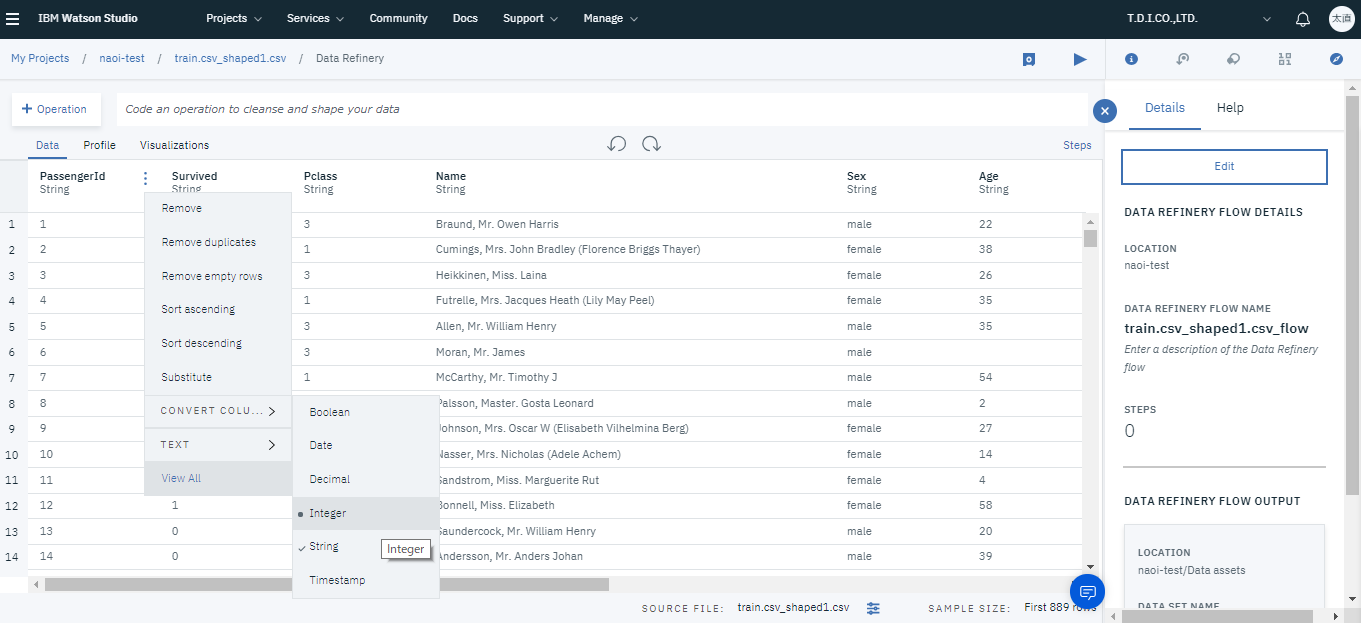
上記の設定を行ったら画面上部の再生ボタンをクリックし処理を行い保存してください。これでトレーニングデータの準備が完了です。
3.モデルの作成
トレーニング用データの準備まで完了したら、機械学習のモデル作成に取り組んでいきましょう。
まずプロジェクトのトップページからAdd to projectを選択しWATSON MACHINE LEARNINGを選択します。
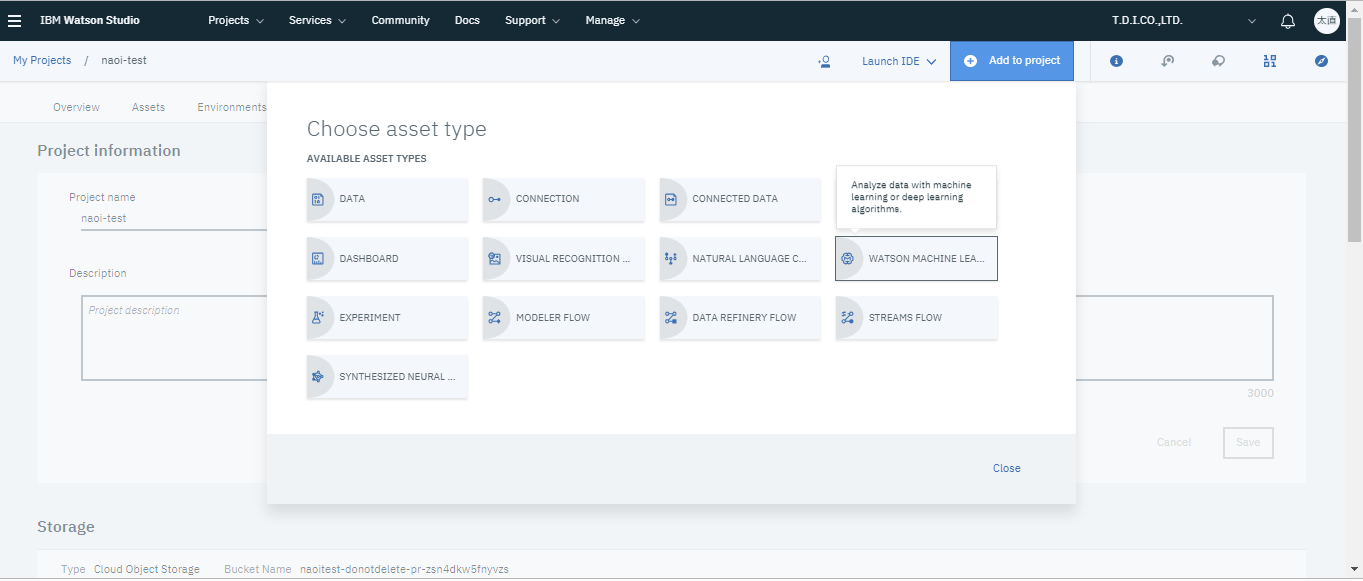
Machine Learning Serviceの欄には環境の準備で作成したMachine Learningのインスタンスを選択します。
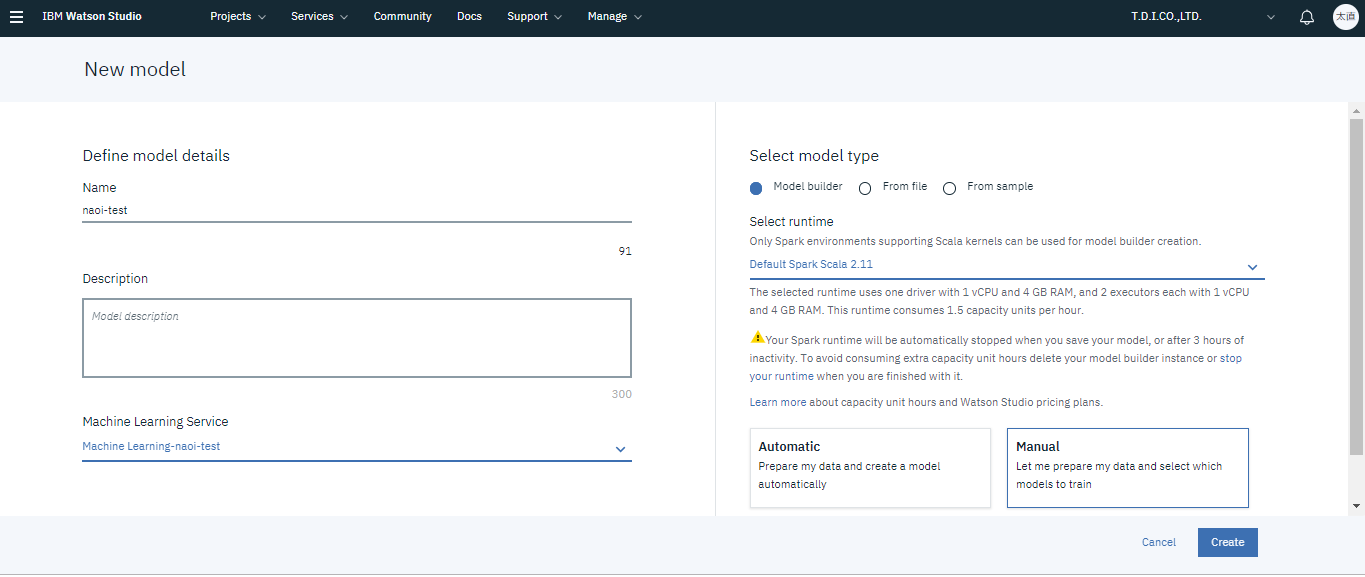
Model TypeはModel builder、runtimeはデフォルトのものにします。そしてCreateを選択すると機械学習プロジェクトが開始されます。
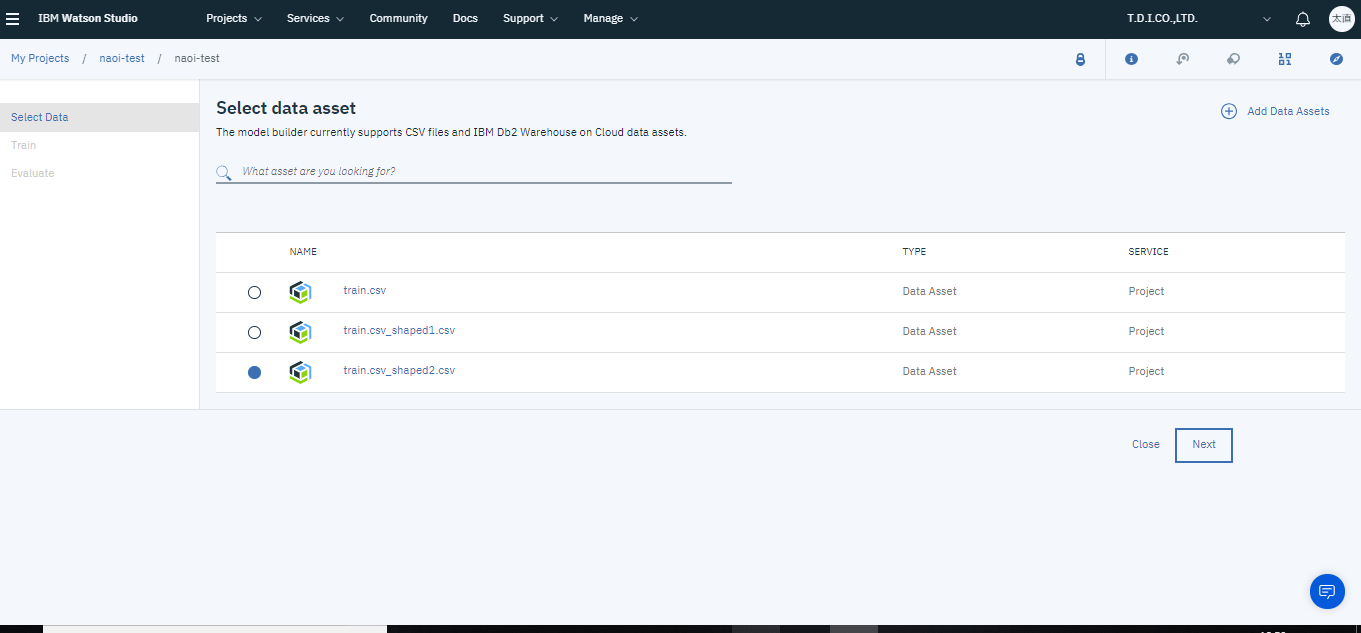
新しいモデルの作成が完了したら、トレーニングデータの選択を行います。ここでは先ほど加工を行ったデータを選択します。
次に予測対象の列、トレーニングに用いる列、作成モデルの種類を選択します。
今回は生き残れるかを予測したいのでColumn value to predictにはSurvivedを、そして予測には予測対象以外の全ての列を用いたいのでFeature columnsにはAllを選択します。また、今回は生きるか死ぬかの2択なのでBinary Classification(2値分類)を選択します。
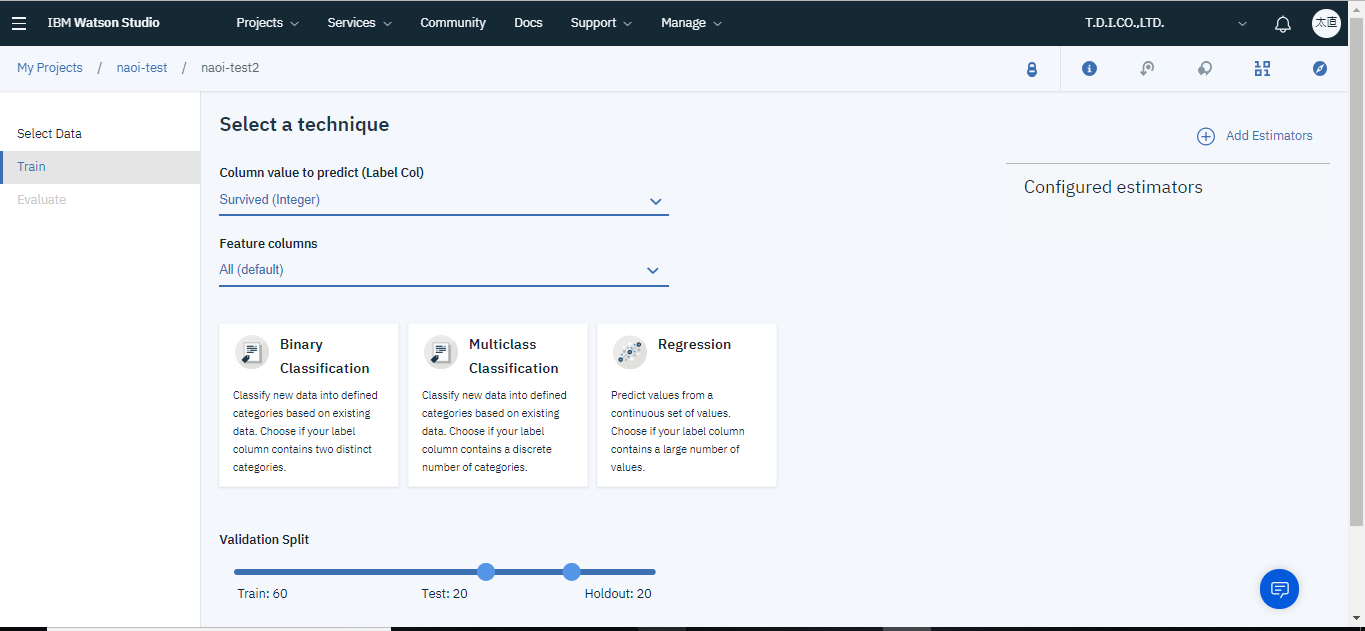
次に学習方法を追加します。
今回はランダムフォレスト(Random Forest Classifier)、ロジスティック回帰(Logistic Regression)、勾配ブースティング決定木(Gradient Boosted Tree Classifier)、決定木(Decision Tree Classifier)の4つすべての方法のモデルを作成し比較してみます。4つの方法をそれぞれクリックしAddをクリックします。
 そしてNextを押したらモデルの作成が始まります。
そしてNextを押したらモデルの作成が始まります。
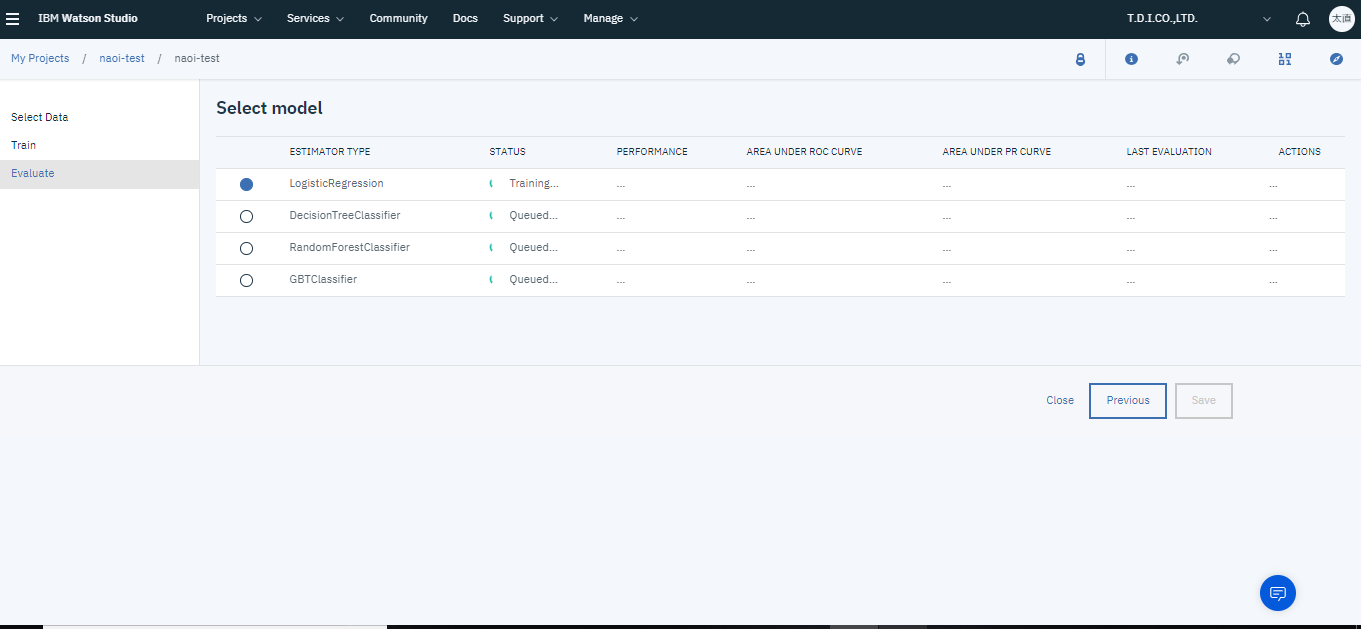
モデル作成画面で4つのモデルのSTATUSがそれぞれTrained & Evaluatedになったらトレーニング完了です。
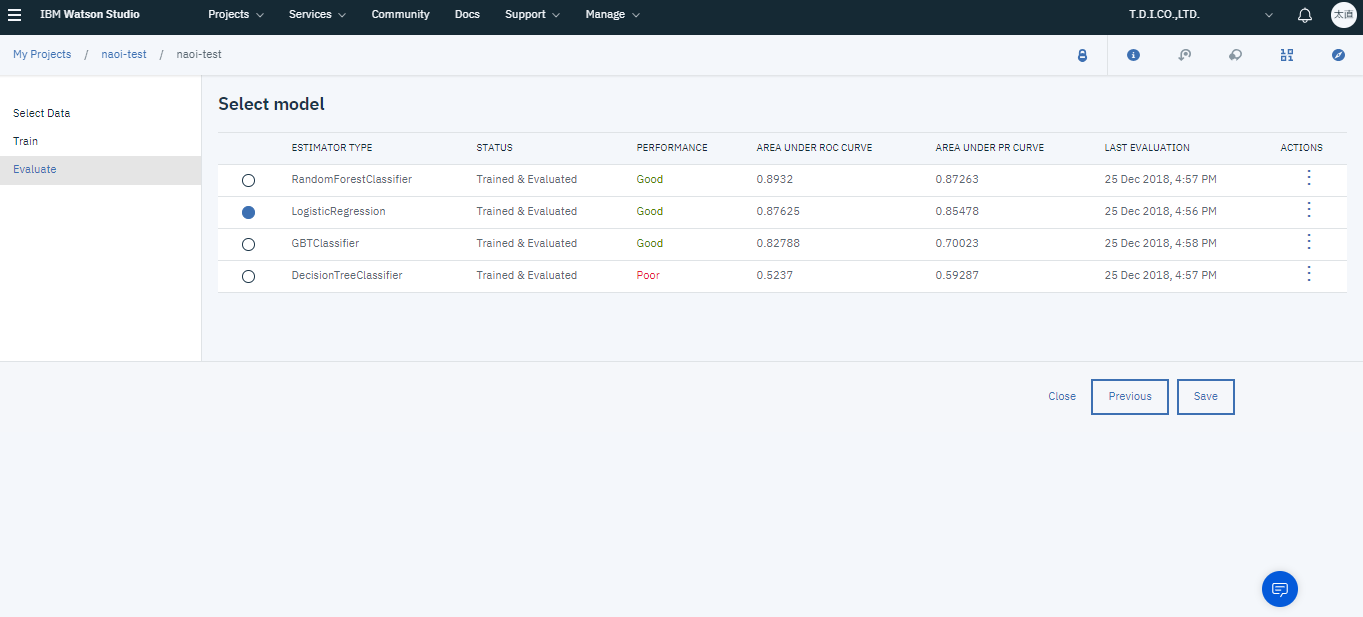
今回はROC曲線下の面積が最大であった、ランダムフォレストのモデルを保存します。
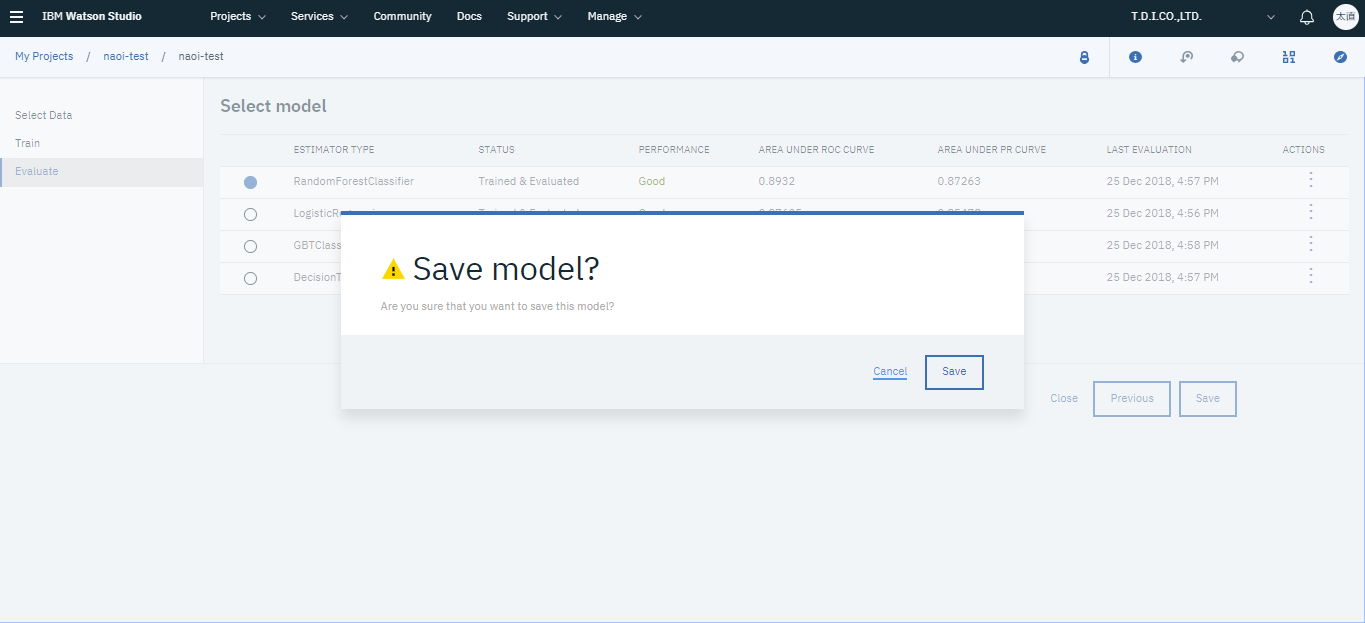
保存するモデルを選択し、Saveをクリックすればモデルを保存できます。
4.モデルのデプロイ
保存が完了すると、モデルの詳細画面が立ち上がります。
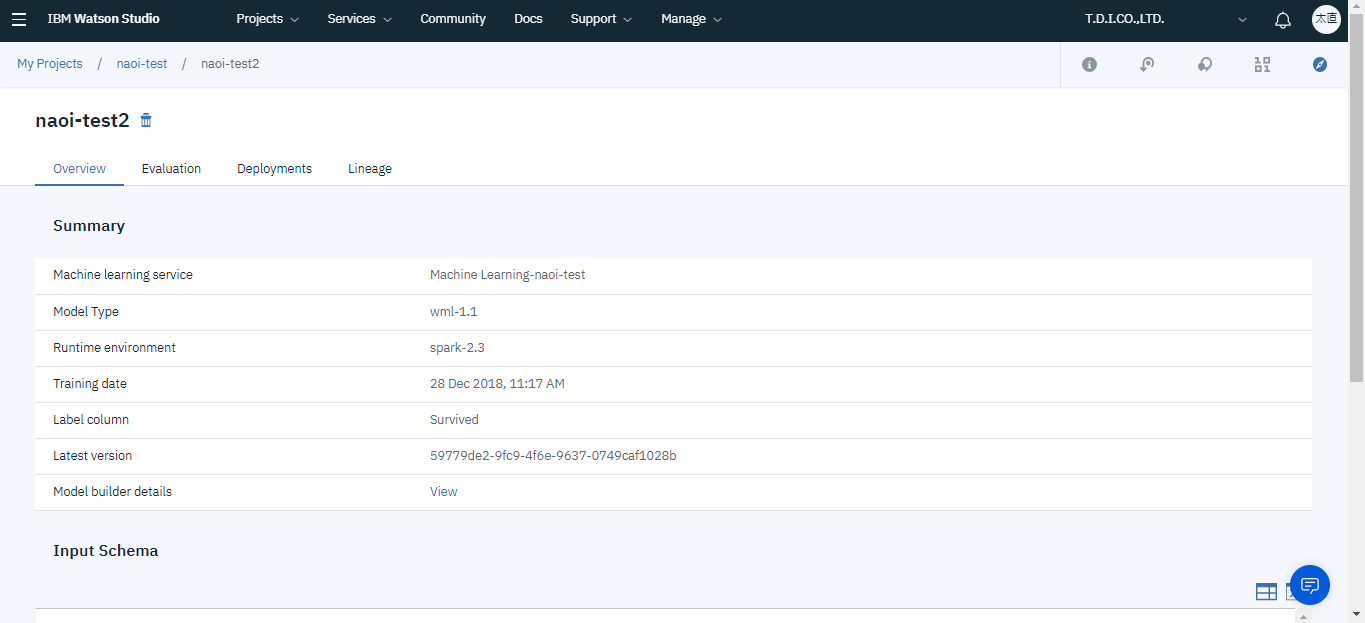
ここでDeploymentsタブを選択しサービス名を入力、saveをクリックするとサービスのデプロイが完了します。デプロイを行う事でブラウザから予測モデルを使用することができます。STATUSがDEPLOY_SUCCESSになればデプロイ完了です。
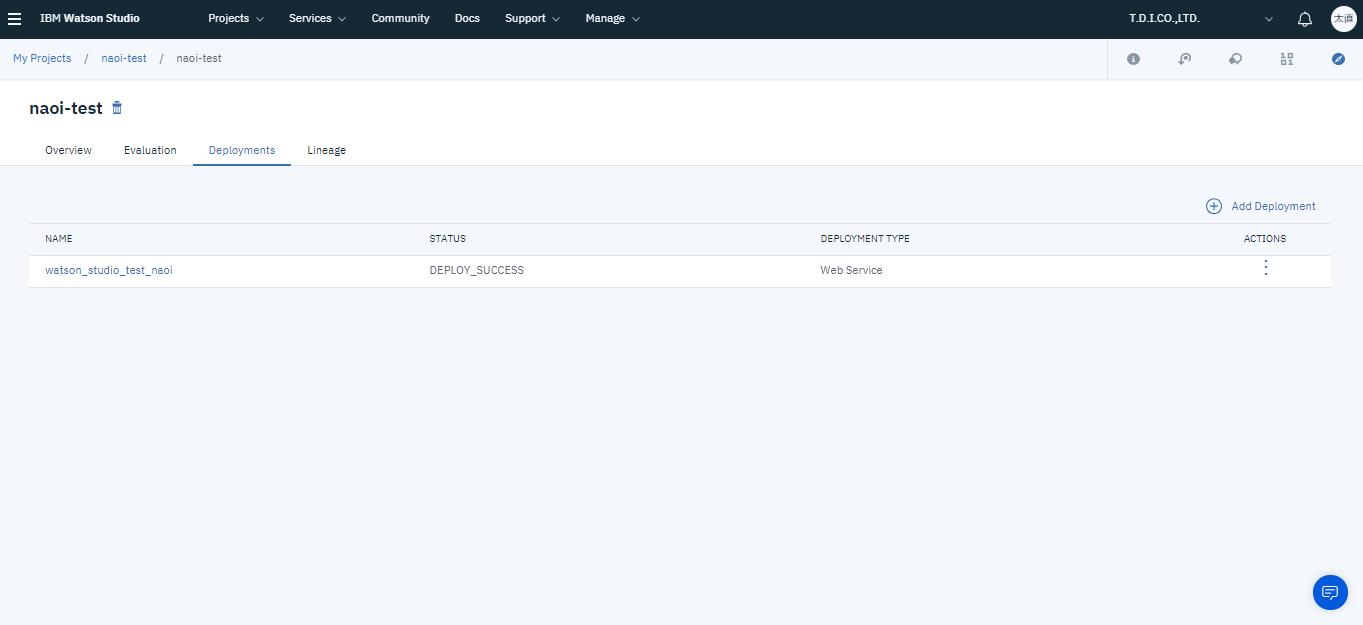
5.モデルの使用
プロジェクト管理画面のDeploymentsタブを開きます。
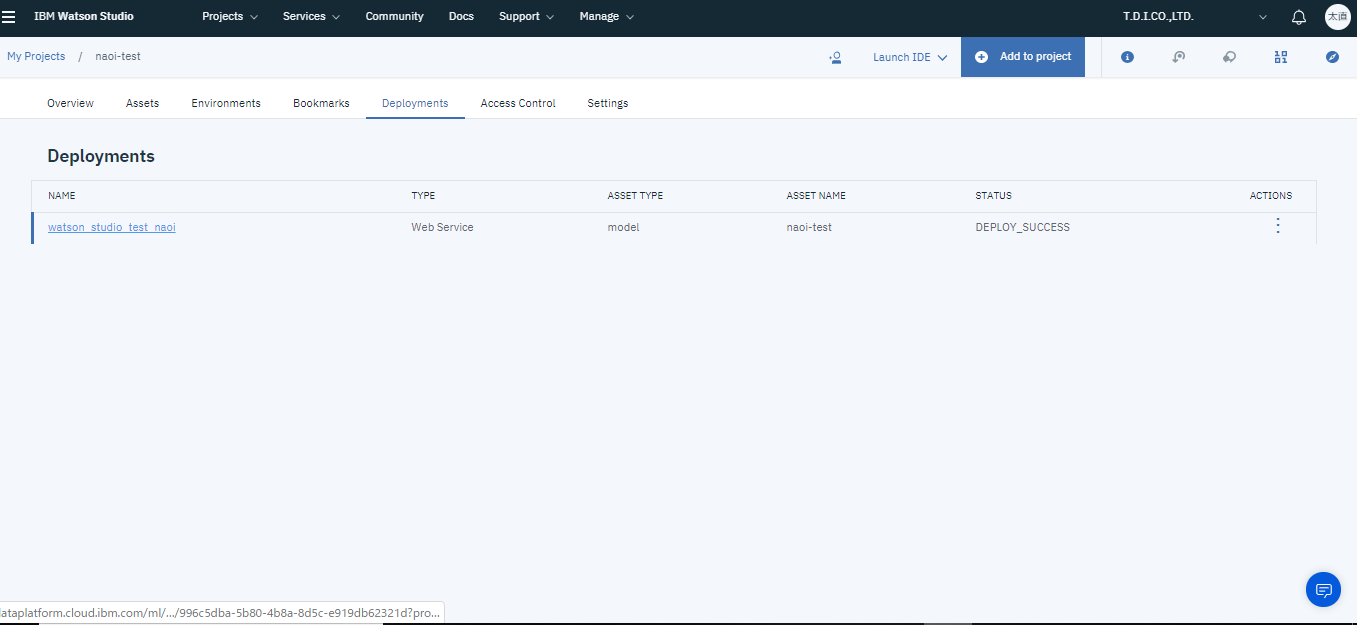
そこでサービス名をクリックしTestタブを選択するとテスト画面が立ち上がるので各列にデータを入力すると、予測を行う事ができます。
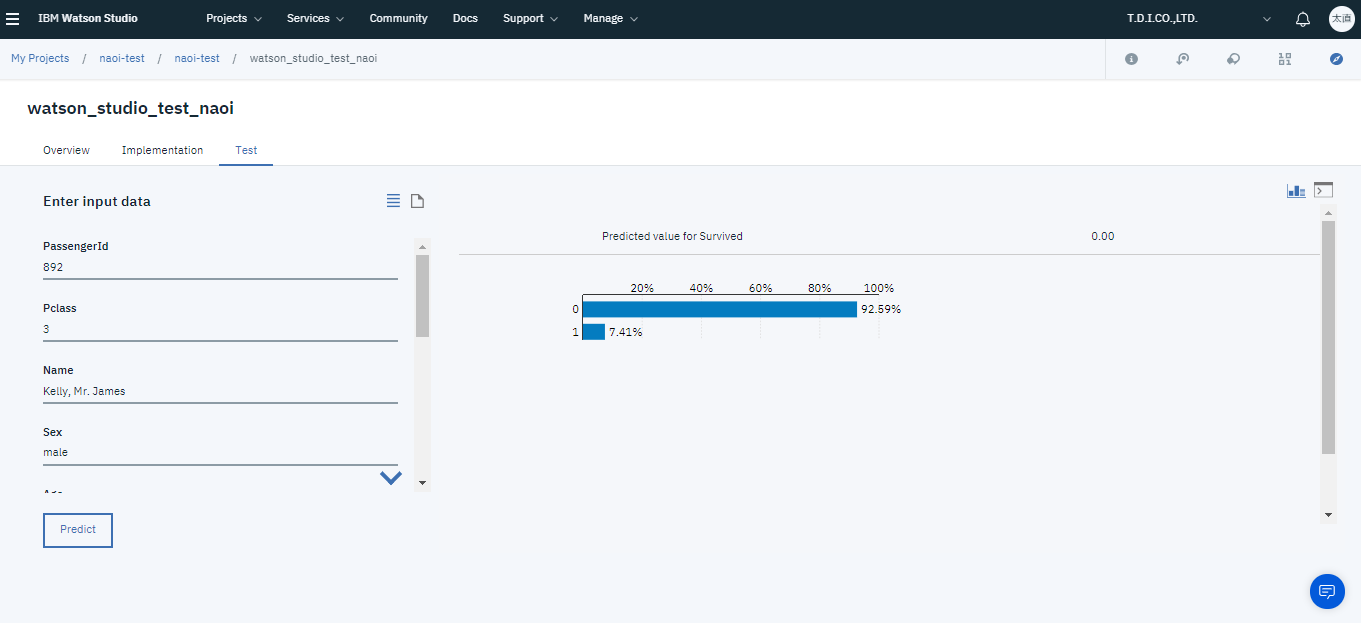
上が実際に予測を行った結果になります。今回はkaggleで答えまで公開されていたので、正解もすぐわかります。こちらが実際の答えになります。
このように今回作成したモデルの予測結果と一致していることが確認できます。
最後に
お読みいただき、ありがとうございました。今回初めて機械学習に挑戦してみましたが、私のような新米エンジニアでも簡単にモデルの作成からデプロイが行えてしまう事に驚きました。今回の内容では肝心の予測方法について選択肢から選ぶ形でしたが、SPSS Modelerフローを用いて自分でニューラルネットワークを構築できるようなので、今後はそういったことにも挑戦していこうと思います。

執筆者プロフィール

- tdi AI・コグニティブ推進部
-
文系出身の新米エンジニアです。これまでに行ってきたことは、ツール開発や画像認識、チャットボットの運用などです。
今後は機械学習についてもっと詳しくなりたいと思っています。




